内部実装から理解するRenovateの処理の流れ
Renovateはアプリケーションで使用している依存ライブラリを更新するためのPull Requestを自動で作成してくれるソフトウェアです。 柔軟な設定が可能で便利な反面、設定項目は150以上と非常に多く、思い通りに設定するのが難しい場合もあります。
意図した通りに設定するためには、それぞれの設定項目が、どのタイミングで適用されるかを知る必要があります。 そのためにはRenovateがどのように実行されるのかを知るのが有用です。
そこで本記事では、Renovateの内部実装を読みながら処理の流れを見ていきます。 対象のバージョンは執筆時点で最新の v36.19.2 です。
なお、筆者はRenovateの開発に関わる人間ではありません。本記事の内容は筆者がドキュメントやソースコード、実行時のデバッグログなどを読んだ上での理解に基づいています。誤りがありましたらご指摘いただけると幸いです。
前提
普段はGitHub Appとして提供されているものを利用することが多いかもしれませんが、Renovateはオープンソースソフトウェアであり、CLIとして実行できます。
GitHub Appを利用する場合、いつの間にかPull Requestができているという体験になり、内部で行われている処理を意識することは少ないかもしれません。処理の流れを考える際は、RenovateをホストしているMend社の立場で考えてみるとわかりやすいと思います。
実行の流れ
結論から言うと、Renovateは次の流れで実行されます。

1〜3の処理を本記事ではそれぞれフェーズと呼び、repositoryフェーズの処理をステップと呼ぶことにします。 これはドキュメントやソースコードで使われている呼称ではなく、本記事内の便宜上のものです。
1〜3のフェーズは、 lib/workers/global/index.tsの start() 関数内で行われています。それぞれのフェーズはOpen Telemetryで計装されており、 instrument() 関数でラップされています。
以降では、それぞれのフェーズ・ステップを詳しく見ていきます。
1. config
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/global/index.ts#L123-L148
configフェーズでは、設定ファイルや環境変数、コマンド引数で表現される Global config を読み込みます。
ここでの設定ファイルは config.jsなどであり、一般にRenovateの設定としてイメージする renovate.json などとは異なることに注意が必要です。
この時点で、対象のPlatformが決まります。PlatformはGitリポジトリをホストするサービス (GitHubなど)を表します。
なお local はテスト用途の特別なPlatformで、ローカルファイルシステムを参照するのみで、Pull Requestの作成などは行いません。
なお、ここで登場する mergeChildConfig() 関数 は設定をマージするために繰り返し登場するので、覚えておくとコードが読みやすいでしょう。
2. discover
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/global/index.ts#L150-L153
discoverフェーズでは、Platformから対象のGitリポジトリを探します。--autodiscoverオプション を指定した場合は、 --tokenオプション などで指定した権限でアクセス可能なリポジトリを取得します。
3. repository
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/global/index.ts#L169-L195
repositoryフェーズでは、discoverされたリポジトリごとに下記の処理を行います。
repositoryフェーズ内の各ステップの処理は、 workers/repository/index.ts の renovateRepository() 関数内で行われます。
各ステップは、Splitという単位で実行時間を計測されています。 addSplit(<Split名>) がそのSplitが終了することを表します。
3-1. init
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/repository/index.ts#L40-L55
initステップでは、Gitリポジトリをローカルにcloneします。
さらに、リポジトリ内の設定ファイル(renovate.json など)を読み込みます。
この時点で extends で表現された Preset を解決したり、暗号化された設定を復号したりします。
3-2. extract
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/repository/index.ts#L56-L62 https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/repository/process/index.ts/#L114-L139
lib/workers/repository/index.ts で呼び出している extractDependencies() 関数内で、extractステップと次のloopkupステップが実行されます。
extractステップでは、リポジトリのファイルから更新可能性があるパッケージ(いわゆるライブラリ)を抽出します。 更新対象となるベースブランチが複数ある場合は、すべてのベースブランチについて実行されます。
パッケージの抽出にあたっては、さまざまな言語のパッケージマネジャーが Manager として定義されており、有効なManager(デフォルトはすべて)の設定ファイルから更新可能性があるパッケージを抽出します。
regexManagers で正規表現によるカスタムManagerを定義することも可能です。
3-3. lookup
lookupステップでは、extractステップで抽出されたすべてのパッケージについて、更新があるかを確認し、更新先のバージョンを決定します。osvVulnerabilityAlerts が有効な場合は、最初に脆弱性情報も確認します。
パッケージの更新があるかを確認する先であるパッケージレジストリは DataSource として定義されています。
また、更新の種類(Major/Minorなど)を判断するためのバージョンニングポリシーは Versioning として定義されています。
3-4. onboarding
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/repository/index.ts#L63-L73
onboardingステップでは、Renovateが未設定の場合に、オンボーディング(Renovateの導入)のためのPull Requestを作ります。
3-5. update
該当箇所: https://github.com/renovatebot/renovate/blob/36.19.2/lib/workers/repository/index.ts#L75-L79
updateステップでは、Renovateが設定済みの場合に、パッケージを更新するためのPull Requestを作ります。 このステップでは、大まかに言えば次の処理が行われます。
- packageファイル (
package.jsonなど) を更新 - lockファイル (
package-lock.jsonなど。artifactと呼ばれる) を更新 - ブランチを作成
- コミットを作成
- Pull Requestを作成
- 設定されていれば自動マージ
updateステップの後に行われる後処理については、本記事では割愛します。
まとめ
本記事ではRenovateの処理の流れを見てきました。
普段Renovateの設定を書く際は、configフェーズとdiscoverフェーズを意識する必要はほとんどなく、repositoryフェーズのステップを意識すれば十分です。その中でもonboardingステップは初回だけの特殊な処理なので除くと、基本的にはリポジトリごとに以下の順序で実行されることを覚えておくと良いでしょう。
- init: リポジトリをローカルにcloneする
- extract: リポジトリのファイルから更新可能性があるパッケージを抽出する
- lookup: 抽出されたすべてのパッケージについて、更新があるかを確認し、更新先のバージョンを決定する
- update: Renovateが設定済みなら更新するためのPull Requestを作る
CLIの--dry-run オプションを使う際にも、指定する値ごとに実行される処理がイメージつきやすくなるかと思います。また、それぞれのステップでどの設定が参照されるかは、改めて別の記事を書きたいと考えています。
参考
ぷよぷよプログラミングをReactにしてみた
10代のプログラミングをやり始めたばかりの頃に、ちょっとしたゲームを作ったこともあったけど、長い間遠ざかっていた。一般的なGUIのアプリケーションがイベント駆動で処理を行うのに対し、ゲームは自分でメインループを回して毎フレーム描画するもの*1で、プログラムの書き方が変わってくる。
自分はWebアプリケーションを得意分野としており、ゲームにはやや苦手意識を持っていたが、 ぷよぷよプログラミング が話題になっていたので、とりあえずMonacaで4行追記するだけの基礎コースで始めてみた。
動くようになった後でソースコードを詳しく読もうにも、DOMの操作が混じっていると処理が追いづらいので、ゲームのStateから宣言的に描画される形にしたかった。というわけでReact + TypeScript にリファクタリングしてみた*2。
原型をあまり大きく崩さないようにはしたつもり。メインループは Gameコンポーネント に移動している。requestAnimationFrameで1フレーム分の処理を行う関数を実行し、ReactのStateで保持してる現在のフレーム数を増やすことで、毎フレーム再レンダリングしている。
既存コードの都合で、グローバル変数の副作用がたくさんあるので、Reactの Strict Mode を使っていると、ゲームの mode をStateにしようとしたときに正しく動かなかった。副作用を完全になくすほどのモチベーションはなかった。
React化してGameの一部の状態をStateに持つようにしたら、わけわからん状態遷移するようになってしまった。だいぶ時間を浪費したけど、どうやらReactのStrict ModeがsetStateの更新関数を2回呼び出すおかげっぽい。
— かと (@orangain) 2022年1月10日
Twitterのスレッドに書いたけど、普段とは違うコードを読み、いろんな発見があって楽しかった。このような素晴らしい教材を無料で公開してくださっているセガ様に感謝です。
2021年を振り返って
2021年を振り返って
このブログでの2021年の記事は1件のみで、個人としてのアウトプットが少ない1年となりました。 勤務先での開発は相変わらず楽しくやってますが、それ以外の時間は疲れていることが多かったというのが正直なところです。 家にいる時間は昨年に引き続き長かったので、途中で引っ越して住環境が改善したのは良い変化でした。
2022年に向けて
勤務先の開発においても学びをアウトプットできていないところがあるので、来年の早い段階でアウトプットしていきたいです。
歳のせいで疲れやすくなっている面もあると思うので、負けずに運動していきたいです。 最近はピクミンブルームが歩くモチベーションになっているので、なるべく外に出て歩きたいと思います。
今後ともよろしくお願いいたします。
Ktor Serverのリクエストハンドラーで同期処理を行うと何が起きるのか
Ktor Server はKotlinのコルーチンを活用したWebアプリケーションフレームワークです。 コルーチンによる非同期処理性能を発揮するためには同期処理をなるべく避けるべきですが、例えばJVM言語におけるデータベース接続で広く使われているJDBCでは、同期処理が前提になっています1。
実際のところ、Ktor Serverで同期処理を行なった場合に、どのような挙動になるかよく分かってなかったので、改めて調べてみました。
実験・調査した環境は次の通りです。
- AdoptOpenJDK 11
- Kotlin 1.5.21
- Ktor Server 1.6.2
- Netty 4.1.63
- JDBI 3.21.0
- HikariCP 5.0.0
- Logback Classic 1.2.3
- PostgreSQL 13
結論
結論を先に置いておきます。
Ktor Serverにおいて、リクエストを処理するスレッドはラウンドロビンで順番に割り当てられるので、時間のかかる同期処理があると、後続のリクエストが同期処理の完了を待たされてしまう。
実験用のアプリケーション
動作を確認するために、以下の2種類のエンドポイントをもつアプリケーションを用意しました。2つともPosgreSQLの pg_sleep() 関数で {seconds} 秒だけ待つという動作は同じで、処理を実行するコルーチンコンテキストだけが異なります。
- 同期エンドポイント(
/sleep-sync/{seconds})- リクエストを処理するコルーチンコンテキストで同期処理を行う
- 非同期エンドポイント(
/sleep-async/{seconds})- IO専用のコルーチンコンテキストで同期処理を行う(リクエストを処理するコルーチンコンテキストから見ると非同期)
具体的な実装の違いは以下のとおりです。ソースコード全体はGitHubのリポジトリに置いてあります。
// 同期エンドポイントのクエリ実行 fun sleepSync(seconds: Double): Double { val sql = "SELECT pg_sleep(:seconds)" return jdbi.withHandle<Double, Exception> { handle -> logger.info("sleepSync($seconds)") handle.createQuery(sql).bind("seconds", seconds).mapToMap().list() seconds } } // 非同期エンドポイントのクエリ実行 suspend fun sleepAsync(seconds: Double): Double { val sql = "SELECT pg_sleep(:seconds)" return withContext(Dispatchers.IO) { jdbi.withHandle<Double, Exception> { handle -> logger.info("sleepAsync($seconds)") handle.createQuery(sql).bind("seconds", seconds).mapToMap().list() seconds } } }
挙動の確認
同期エンドポイント
Apache Benchを使って、16リクエストを1並列で送ります。 ab コマンドでは -n で全体のリクエスト数を、 -c で並列実行数を指定します。
$ ab -n 16 -c 1 http://localhost:8080/sleep-sync/0.1
この時のサーバー側のログは次のようになります。各行で時刻の次の [eventLoopGroupProxy-4-X] がスレッド名です。 200 OK: GET - /sleep-sync/0.1 のようなリクエストログは、レスポンスを返す直前に出力されることに注意してください。
これをみると、リクエストを処理するためのスレッドが8個2あり、リクエストごとに順番に使用されていることがわかります。クエリも同じスレッドで実行されています。
19:50:57.808 [eventLoopGroupProxy-4-1] INFO SleepQueryService - sleepSync(0.1) 19:50:57.921 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:57.937 [eventLoopGroupProxy-4-2] INFO SleepQueryService - sleepSync(0.1) 19:50:58.046 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.066 [eventLoopGroupProxy-4-3] INFO SleepQueryService - sleepSync(0.1) 19:50:58.171 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.188 [eventLoopGroupProxy-4-4] INFO SleepQueryService - sleepSync(0.1) 19:50:58.299 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.319 [eventLoopGroupProxy-4-5] INFO SleepQueryService - sleepSync(0.1) 19:50:58.424 [eventLoopGroupProxy-4-5] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.429 [eventLoopGroupProxy-4-6] INFO SleepQueryService - sleepSync(0.1) 19:50:58.535 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.541 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 19:50:58.652 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.657 [eventLoopGroupProxy-4-8] INFO SleepQueryService - sleepSync(0.1) 19:50:58.767 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.772 [eventLoopGroupProxy-4-1] INFO SleepQueryService - sleepSync(0.1) 19:50:58.880 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.885 [eventLoopGroupProxy-4-2] INFO SleepQueryService - sleepSync(0.1) 19:50:58.991 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:58.995 [eventLoopGroupProxy-4-3] INFO SleepQueryService - sleepSync(0.1) 19:50:59.103 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:59.108 [eventLoopGroupProxy-4-4] INFO SleepQueryService - sleepSync(0.1) 19:50:59.219 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:59.224 [eventLoopGroupProxy-4-5] INFO SleepQueryService - sleepSync(0.1) 19:50:59.332 [eventLoopGroupProxy-4-5] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:59.336 [eventLoopGroupProxy-4-6] INFO SleepQueryService - sleepSync(0.1) 19:50:59.446 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:59.451 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 19:50:59.562 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 19:50:59.567 [eventLoopGroupProxy-4-8] INFO SleepQueryService - sleepSync(0.1) 19:50:59.677 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1
abの結果は長くなるので抜粋しますが、特に変わった点はありません。
Requests per second: 7.93 [#/sec] (mean) Time per request: 126.029 [ms] (mean) ... Percentage of the requests served within a certain time (ms) 50% 116 66% 117 75% 124 80% 124 90% 128 95% 264 98% 264 99% 264 100% 264 (longest request)
非同期エンドポイント
同様のリクエストを非同期バージョンのエンドポイントにも送ります。
$ ab -n 16 -c 1 http://localhost:8080/sleep-async/0.1
ログを確認すると、今度はクエリが DefaultDispatcher-worker-1 というスレッドで実行されています。
19:54:16.137 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.243 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.249 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.359 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.364 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.474 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.479 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.588 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.590 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.694 [eventLoopGroupProxy-4-5] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.697 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.804 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.806 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:16.950 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:16.955 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.064 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.070 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.181 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.186 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.293 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.297 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.406 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.411 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.520 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.526 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.639 [eventLoopGroupProxy-4-5] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.644 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.752 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.758 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.869 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:54:17.875 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:54:17.986 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-async/0.1
abの結果も大きく違いません。
Requests per second: 8.58 [#/sec] (mean) Time per request: 116.610 [ms] (mean) ... Percentage of the requests served within a certain time (ms) 50% 115 66% 116 75% 117 80% 117 90% 123 95% 146 98% 146 99% 146 100% 146 (longest request)
先ほどは1並列だったのでWorkerは1スレッドしか使われていませんが、次のように並列度を上げると複数のスレッドが使われます。
$ ab -n 16 -c 16 http://localhost:8080/sleep-async/0.1
19:56:20.354 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.465 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.474 [DefaultDispatcher-worker-1] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.494 [DefaultDispatcher-worker-6] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.494 [DefaultDispatcher-worker-5] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.498 [DefaultDispatcher-worker-7] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.498 [DefaultDispatcher-worker-2] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.498 [DefaultDispatcher-worker-3] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.500 [DefaultDispatcher-worker-12] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.502 [DefaultDispatcher-worker-11] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.502 [DefaultDispatcher-worker-8] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.502 [DefaultDispatcher-worker-9] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.583 [DefaultDispatcher-worker-14] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.583 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.609 [DefaultDispatcher-worker-10] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.609 [eventLoopGroupProxy-4-5] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.610 [DefaultDispatcher-worker-13] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.610 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.615 [DefaultDispatcher-worker-21] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.615 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.615 [DefaultDispatcher-worker-4] INFO SleepQueryService - sleepAsync(0.1) 19:56:20.616 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.616 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.617 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.621 [eventLoopGroupProxy-4-5] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.621 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.622 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.693 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.718 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.721 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.723 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-async/0.1 19:56:20.723 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-async/0.1
スロークエリがある場合
同期処理(クエリ)の実行時間が短い場合は大きな差が生まれませんが、実行時間が長いリクエストがあると差が生まれます。
同期バージョンのスロークエリ
1つだけ20秒かかるスロークエリがある状況を再現してみます。
$ curl http://localhost:8080/sleep-sync/20
を裏で実行した後に、abを実行します。
$ ab -n 50 -c 50 http://localhost:8080/sleep-sync/0.1
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /sleep-sync/0.1
Document Length: 3 bytes
Concurrency Level: 50
Time taken for tests: 19.255 seconds
Complete requests: 50
Failed requests: 0
Total transferred: 4100 bytes
HTML transferred: 150 bytes
Requests per second: 2.60 [#/sec] (mean)
Time per request: 19254.631 [ms] (mean)
Time per request: 385.093 [ms] (mean, across all concurrent requests)
Transfer rate: 0.21 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 3 0.9 3 4
Processing: 116 2622 6061.2 464 19137
Waiting: 112 2622 6061.2 463 19137
Total: 117 2625 6061.1 466 19138
Percentage of the requests served within a certain time (ms)
50% 466
66% 574
75% 688
80% 688
90% 18699
95% 18922
98% 19138
99% 19138
100% 19138 (longest request)
最後のリクエスト処理時間の分布を見ると、それぞれのクエリ自体は0.1秒で終わるにもかかわらず、20秒近く待たされているリクエストがあることがわかります。
ログを見ると以下のようになっており、スロークエリを処理しているのと同じスレッド eventLoopGroupProxy-4-7 に当たってしまったリクエストがスロークエリの完了を待たされています。7/8 = 87.5%のリクエストは待たされずに終わるので、リクエスト処理時間の分布において80%と90%の間に大きな差があることを説明できます。
20:14:29.031 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(20.0) 20:14:30.467 [eventLoopGroupProxy-4-8] INFO SleepQueryService - sleepSync(0.1) 20:14:30.575 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:30.583 [eventLoopGroupProxy-4-8] INFO SleepQueryService - sleepSync(0.1) 20:14:30.589 [eventLoopGroupProxy-4-6] INFO SleepQueryService - sleepSync(0.1) 20:14:30.589 [eventLoopGroupProxy-4-3] INFO SleepQueryService - sleepSync(0.1) 20:14:30.589 [eventLoopGroupProxy-4-1] INFO SleepQueryService - sleepSync(0.1) 20:14:30.589 [eventLoopGroupProxy-4-5] INFO SleepQueryService - sleepSync(0.1) 20:14:30.590 [eventLoopGroupProxy-4-4] INFO SleepQueryService - sleepSync(0.1) 20:14:30.590 [eventLoopGroupProxy-4-2] INFO SleepQueryService - sleepSync(0.1) 20:14:30.699 [eventLoopGroupProxy-4-8] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:30.699 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:30.699 [eventLoopGroupProxy-4-3] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 ... 20:14:31.266 [eventLoopGroupProxy-4-4] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:31.267 [eventLoopGroupProxy-4-2] INFO SleepQueryService - sleepSync(0.1) 20:14:31.266 [eventLoopGroupProxy-4-1] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:31.266 [eventLoopGroupProxy-4-6] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:31.375 [eventLoopGroupProxy-4-2] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:49.051 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/20 20:14:49.055 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 20:14:49.163 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:49.164 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 20:14:49.274 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:49.275 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 20:14:49.386 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:49.387 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 20:14:49.499 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:49.500 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 20:14:49.607 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1 20:14:49.608 [eventLoopGroupProxy-4-7] INFO SleepQueryService - sleepSync(0.1) 20:14:49.717 [eventLoopGroupProxy-4-7] INFO ktor.application - 200 OK: GET - /sleep-sync/0.1
非同期バージョンのスロークエリ
非同期バージョンのスロークエリを裏で実行した場合は、他のリクエストがスロークエリに待たされることはなく、短時間で完了します。
$ curl http://localhost:8080/sleep-async/20
$ ab -n 50 -c 50 http://localhost:8080/sleep-async/0.1
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /sleep-async/0.1
Document Length: 3 bytes
Concurrency Level: 50
Time taken for tests: 0.810 seconds
Complete requests: 50
Failed requests: 0
Total transferred: 4100 bytes
HTML transferred: 150 bytes
Requests per second: 61.75 [#/sec] (mean)
Time per request: 809.659 [ms] (mean)
Time per request: 16.193 [ms] (mean, across all concurrent requests)
Transfer rate: 4.95 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 4 2.0 4 8
Processing: 123 374 182.4 354 686
Waiting: 115 374 182.6 354 686
Total: 123 378 181.6 357 689
Percentage of the requests served within a certain time (ms)
50% 357
66% 472
75% 578
80% 581
90% 583
95% 687
98% 689
99% 689
100% 689 (longest request)
結論
結論としては、次の通りです。
Ktor Serverにおいて、リクエストを処理するスレッドはラウンドロビンで順番に割り当てられるので、時間のかかる同期処理があると、後続のリクエストが同期処理の完了を待たされてしまう。
最後に、Ktor Serverにおける同期処理への向き合い方を的確に表す質問への回答があったので、引用しておきます。
Ktor, how to deal with jdbc blocking calls - Kotlin Discussions
- If operations are fast and you are sure that they won’t block forever, you can call them inside coroutines.
- If operations are long, but you have only few of them, you can use custom CoroutineContext with increased number of parallel threads.
- If you have a large number of those blocking operations, you should just good old executor. If you want to evaluate the result, you can create a Channel and send results to it.
-
参考: https://yakubouzu.hatenablog.com/entry/2020/07/24/114509↩
-
スレッド数は、callGroupSize という設定で変更でき、デフォルト値は
Runtime.getRuntime().availableProcessors()(利用可能なコア数)です。↩
2020年を振り返って
2020年を振り返って
2020年は大変な一年となり、家に居る時間が圧倒的に増えました。元からインドア派なことや、リングフィットアドベンチャーやFitDeskなどの室内で運動する手段があったことから、それほど体調を崩すこともなく暮らせたのは幸いでした。
勤務先では、新規事業の比較的初期からのメンバーとして携わっていたサービスをローンチでき、好評いただけたのはとても嬉しい経験でした。その中で得た知見をこのブログや勤務先のブログなどでアウトプットできました。
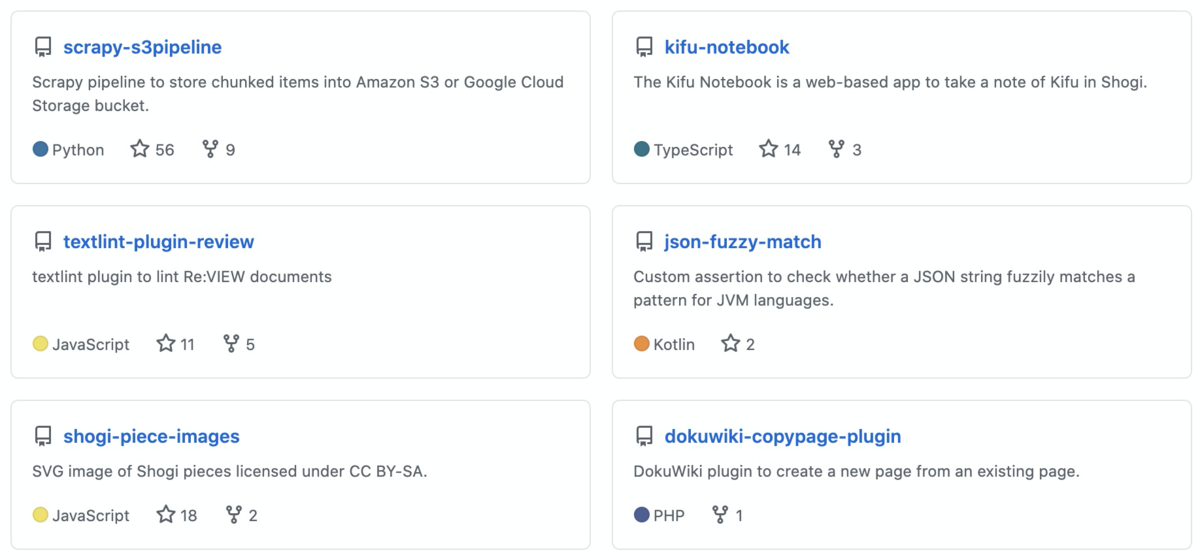
最近GitHubで公開しているリポジトリのいくつかに2桁のStarがついていることに気づきました。自分の書いたコードが誰かの役に立っているのは嬉しい限りです。
2021年に向けて
勤務先の立ち上がったサービスを拡大させていけるかどうか、この1年にかかっていると思うので、気合を入れて頑張っていきたいと思います。技術的な課題は山積みですが、サービスの成長に合わせて自身も成長していけそうで楽しみです。
Cloud Run(フルマネージド)でリクエスト外に処理をすると200倍遅くなる
はじめに
Cloud Runはサーバーレスなコンテナ実行基盤です。この記事ではフルマネージド版のCloud Runのみを対象とし、フルマネージド版のCloud Runを指して、単にCloud Runと表記します。
Cloud Runの料金プランの特徴として、リクエストの実行中のみ課金対象になるという点が挙げられます。しかし、リクエストのたびにコンテナの起動と終了を繰り返すわけではなく、起動したコンテナはある程度使い回されます。リクエストが無い間は、コンテナが起動していても課金されないというわけです。

だからと言って無料で使い放題というわけではなく、コンテナランタイムの契約として、リクエスト中しかCPUが使えないと明記されています
You should only expect to be able to do computation within the scope of a request: a container instance does not have any CPU available if it is not processing a request.
https://cloud.google.com/run/docs/reference/container-contract?hl=ja より引用
ですが、実際にデプロイしたアプリケーションの挙動を見る限り、まったくCPUが使えないわけではなく、リクエスト外でも処理は動いています。例えばコネクションプールライブラリのHikariCPを使っていると、30秒に1回コネクションプールがメンテナンスされ、必要に応じて再接続するログが出力されます。
あるCloud Runアプリケーションで、レスポンスを返した直後に追加で処理を行っていました。リクエスト中に処理した方が良いことは知っていましたが、動いてるならまあいいかと放置していたら、運用中にエラーが発生してしまいました。そこで、Cloud Runでリクエスト外に処理を行った場合の挙動を改めて実験してみました。実験結果は2020-05-17時点のもので、今後変わる可能性があることに留意してください。
実験方法
リクエストを受けるたびに、同じ処理を以下のタイミングで3回行うアプリケーションを作成し、それぞれの実行時間を計測しました。
- (A) リクエスト中(レスポンスを返す前)
- (B) レスポンスを返した直後
- (C) Bの完了後、1秒経過してから
以下の3種類のワークロードで実験しました。
- 乱数生成
- Cloud Tasksのタスク作成
- Cloud SQLへのINSERT
実験用のコードを抜粋するとこんな感じになります。KotlinとKtorで書きました。詳しくはリポジトリを参照してください。
routing {
post("/calc") {
calc() // (A) リクエスト中
call.respondText("OK", status = HttpStatusCode.Created)
}
}
intercept(ApplicationCallPipeline.Call) {
proceed()
if (call.request.httpMethod == HttpMethod.Post) {
when (call.request.uri) {
"/calc" -> {
calc() // (B) レスポンスを返した直後
delay(1000)
calc() // (C) Bの完了後、1秒経過してから
}
}
}
}
実験結果
初回はキャッシュなどの影響で (A) リクエスト中の実行時間が相対的に長くなるので無視して、5回計測した結果を掲載します。実行時間の単位はmsです。
1. 乱数生成
ランダムなUUID v4を10万個生成するのにかかる時間を計測しました。アプリケーションは -Djava.security.egd=file:/dev/./urandom をつけて実行しています。
| 試行 | (A) リクエスト内の 実行時間 |
(B) リクエスト直後の 実行時間 |
(C) リクエスト外の 実行時間 |
何倍遅いか (C/A) |
|---|---|---|---|---|
| 1回目 | 123 | 5379 | 33600 | 273.2 |
| 2回目 | 124 | 5431 | 36899 | 297.6 |
| 3回目 | 128 | 8431 | 30907 | 241.5 |
| 4回目 | 123 | 4804 | 35000 | 284.6 |
| 5回目 | 124 | 5246 | 35699 | 287.9 |
2. Cloud Tasksのタスク作成
Cloud Tasksのタスクを作成するのにかかる時間を計測しました。
| 試行 | (A) リクエスト内の 実行時間 |
(B) リクエスト直後の 実行時間 |
(C) リクエスト外の 実行時間 |
何倍遅いか (C/A) |
|---|---|---|---|---|
| 1回目 | 250 | 4014 | 9801 | 39.2 |
| 2回目 | 175 | 2378 | 27700※ | 158.3 |
| 3回目 | 313 | 2072 | 10300 | 32.9 |
| 4回目 | 222 | 1913 | 13001 | 58.6 |
| 5回目 | 239 | 3510 | 11899 | 49.8 |
※ DEADLINE_EXCEEDED: deadline exceeded after 19.700177855s. と例外が発生したので、例外が発生するまでの時間を実行時間としました。
3. Cloud SQLへのINSERT
Cloud SQLのテーブルにINSERTするSQLを実行するのにかかる時間を計測しました。
| 試行 | (A) リクエスト内の 実行時間 |
(B) リクエスト直後の 実行時間 |
(C) リクエスト外の 実行時間 |
何倍遅いか (C/A) |
|---|---|---|---|---|
| 1回目 | 12 | 9 | 2610 | 217.5 |
| 2回目 | 11 | 9 | 1900 | 172.7 |
| 3回目 | 9 | 8 | 1500 | 166.7 |
| 4回目 | 10 | 11 | 2400 | 240.0 |
| 5回目 | 13 | 9 | 1492 | 114.8 |
考察
ワークロードによって異なりますが、(C) リクエスト外の実行時間は、(A) リクエスト内の実行時間に比べて30倍〜300倍程度遅くなることがわかりました。やはりCPUの実行が制限されているようです。
(B) リクエスト直後の実行時間が (C) より短くなるのは、アプリケーションがレスポンスを返した直後はまだリクエスト内だとみなされる時間が少しだけあり、その間に処理が進むためだと考えられます。
なお、リクエスト外に処理を行っていても、そのタイミングでちょうどアプリケーションにリクエストが来ると、リクエスト内とみなされて、CPU割り当てが元に戻って処理が進むようになります*1。このため、アプリケーションへのリクエストが多いときには、リクエスト外で処理をしていても問題が顕在化しないことがあります。
まとめ
実験から、Cloud Runでリクエスト外に処理を行うと、30倍〜300倍程度遅くなることがわかりました。 コンテナランタイムの契約にある通り、Cloud Runで実行するアプリケーションは、リクエストの外で処理を行うことがないようにしましょう。
monorepoのCI/CDで変更された部分だけをビルド/デプロイする
2020-07-11: Cloud Buildでの記述が誤っていたので修正しました。
はじめに
今年のゴールデンウィークは暇があり、勤務先で複数のリポジトリを使っているのが辛く感じてきていたため、monorepoについて調べてみました。monorepoについての説明やメリットについては他の記事に譲ります。
この参考記事でmonorepoの本当の課題として挙げられている以下の4点のうち、3点目に相当する「CIで変更によって影響を受けた部分だけをビルドする方法」を調査・検討しました。
- トランクベース開発は、より一段と重要になります
- すべてのサービスがモノレポで上手く動くわけではありません
- より精巧なCIセットアップが必要です
- あなたは大規模な変更について考える必要があります
この参考記事ではnxが挙げられていますが、nxは主にJavaScriptのプロジェクトを対象としたツールのようなので、言語に依存しない方法を検討しました。
前提
以下の前提で話を進めます。
- monorepoのローカル開発環境でのビルドは既に構成されている。
- 実装例としてGradleのマルチプロジェクトビルドを使いますが、特定の言語やビルドツールに限定した内容ではありません。
- ソースコードのバージョン管理にはGitを使っている。
- masterブランチとfeatureブランチによるPull Requestベースの開発を行っている。
- developブランチを使っていてはダメというものではありません。
どうやって変更された部分を特定するか
まず、変更された部分を特定する方法を考えます。
案1: ビルドツールの差分ビルドを活用する(不採用)
GradleやMake、Bazelなどの依存関係を考慮するビルドツールでは、変更された部分だけをビルドする機能が備わっていますが、CI環境でこれに依存するのは得策とは言えません*1。CI環境に前回のビルド結果がキャッシュとして残っていたとしても、そのキャッシュとの差分が実際の変更の差分と一致する保証はないためです。
CIの場合、仮に変更の差分と一致しなくても最終的な成果物をビルドできれば大きな問題はないかもしれません。一方CDの場合、本当は変更がないのにキャッシュの都合でビルドが実行され、デプロイまでされてしまうのは困るというケースがあるかもしれません。
案2: Gitの差分から特定する(採用)
そこで、Gitの差分から変更された部分を特定するのが良さそうです。 git diff --name-only <commit> を使えば現在のHEADと <commit> の間で変更されたファイル名一覧を取得できるので、それで判断するイメージです。
ただ、比較対象とする <commit> の選び方については一考の余地があります。単純な方法としては、featureブランチではmasterブランチとの差分を、masterブランチでは直前のコミット HEAD^ との差分を取る方法があります。masterブランチは絶対にマージでしか更新しない運用であれば大丈夫かもしれませんが、masterブランチに複数のコミットをプッシュしてしまった場合に差分から漏れてしまうので、ちょっと心許ないです。
理想的には、ビルドのトリガーとなったプッシュ(マージ含む)に含まれる差分から判断したいです。この差分を取得できるかどうかはCIツールに依存します。
CIツールでGitの差分から変更された部分を特定する
Travis CIでは、環境変数 TRAVIS_COMMIT_RANGE *2を見れば、そのビルドが対象としているコミットの範囲がわかります。 TRAVIS_COMMIT_RANGE は新しいブランチを新しいコミットなしでプッシュした場合には空になりますが、この場合には差分がないはずなので、特に影響ないと思います。
GitHub Actionsの場合、環境変数などではわからないものの、ワークフローのトリガーで on.push.paths *3を指定すれば、指定したパスが変更された場合のみ実行されるので、ビルド内で git diff する手間なく簡単に実現できます。
CircleCIでは、パイプライン変数 pipeline.git.revision と pipeline.git.base_revision *4を比較すれば近いことができそうですが、新しいfeatureブランチをプッシュしたときには pipeline.git.base_revision が空になってしまうので、もう一工夫必要です。
個人的によく使っているCloud Buildだと、ビルドトリガーの「含まれるファイルフィルター」を設定することで、指定したパスが変更された場合のみビルドを実行できます。GitHubアクションと似ていますが、新しいfeatureブランチをプッシュしたときには、最新のコミットに含まれる差分のみがフィルターの対象になるようで、もう一工夫必要です。
以下のリポジトリに、GitHub Actions, Travis CI, CircleCIの挙動を試した結果を残してあります。参考にしてください。
https://github.com/orangain/understand-github-actions-on-paths
具体的な実装例
というわけで、GitHub Actionsを使ってGradleマルチプロジェクトビルドのプロジェクトで変更があった部分だけビルドするサンプルを作りました。
次のような2つのアプリが2つのライブラリに依存する構成です。

それぞれのアプリに対応するワークフローの設定を含めており、 apps/account-app の設定は次のとおりです。on.push.paths にはアプリのディレクトリに加えて、アプリが依存するライブラリや、Gradleの設定ファイル *.gradle.kts も含めています。これによって、アプリのコードが変更された場合だけでなく、依存関係が変更された場合にも再ビルドできます。
name: Build account-app on: push: paths: - "apps/account-app/**" - "libs/greeter/**" - "libs/profile/**" - "*.gradle.kts" jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-java@v1 with: java-version: '11' - name: Run gradle build run: ./gradlew :apps:account-app:build - uses: actions/upload-artifact@v2 with: path: apps/account-app/build/libs/*.jar
最後に
上記のサンプルプロジェクトは実際に運用したものではありませんが、変更があった部分だけCI/CDの対象とすることができそうな感触が得られました。
最初は単純に差分にファイルが含まれているかどうかで判断するのでは不十分で、依存関係を考慮しないといけないと考えていたため、ちょっとしたツールを実装していましたが、実装してる途中でそのような考慮は不要であることに気付きました。
結果的にこのゴールデンウィークは車輪の再発明をしただけでしたが、GradleのマルチプロジェクトビルドやGitHub Actionsを試したり、トポロジカルソートを実装したりと、いろいろ学べたので良しとします。この記事にも大した新規性はありませんが、少しでも検索に引っかかって再発明する人が減れば幸いです。